
Previously
Over my last few posts I’ve covered pattern matching with regex, how to break down a sentence into recognized parts using a lexer/tokeniser, creating the basic building blocks of a combinatorial parser from an OO perspective and migrated it all to a purely functional approach.
We used a two phase process, firstly a Lexer/Tokeniser, where we turned a string into higher order tokens such as Day, ClockTime and Reserved Words, and a combinatorial expression Parser to process the structure of phrase:
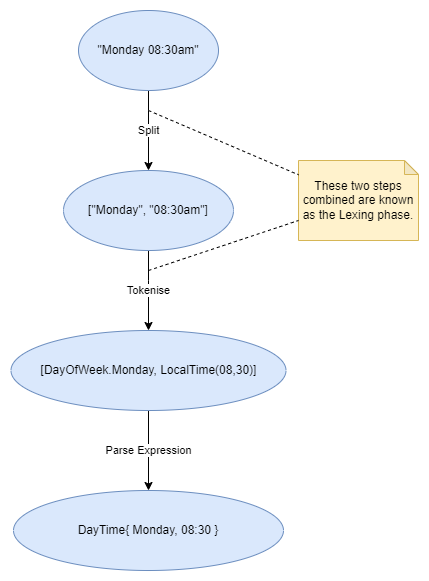
And we applied this process to the following phrases to generate an object:
// Separate two part element context => DayTime range
"Pickup Mon 08:00 dropoff wed 17:00"
// Range elements with different separators => Open Days range and Hours Range
"Open Mon to Fri 08:00 - 18:00"
// Repeating tokens => List of tour times
"Tours 10:00 12:00 14:00 17:00 20:00"
// Repeating complex elements => List of event day times
"Events Tuesday 18:00 Wednesday 15:00 Friday 12:00"
Why two phase
In some of the projects I worked on the goal with the separate tokenisation phase was to keep the language constructs separate from the syntax rules. This would enable us to hot-swap the language pack without touching the syntax rules, and on the flip side, convert any compiled syntax rules into a local language.
I put together a similar example implementation here based off a modified language aware tokeniser.
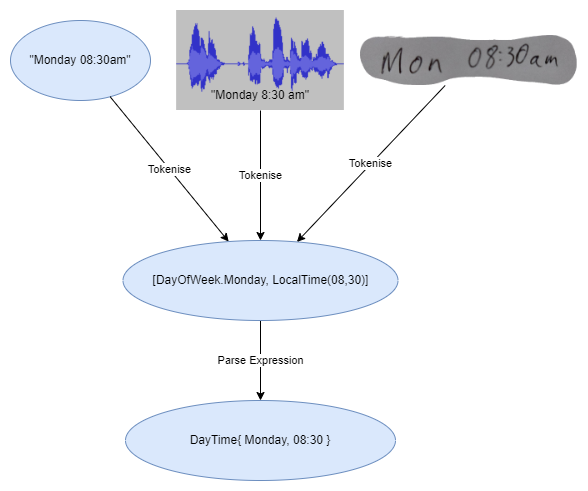
Additionally, it’s entirely possible that you may be Tokenising from a different source, maybe a number of images are being processed as words, or you are processing an audio stream and tokenising that before you analyze it for expression.
What else can a token be?
The first phase of our two phase process is to turn our strings into an array of objects / symbols that represent complete concepts, but what constitutes a complete concept is flexible.
At the end of the day, we need an array of things to work with, and currently they are Token objects. A string is also an array of Char[], and if we consider Character, Digit, Symbol, and Whitespace as our tokens then we can use a string directly as the Token source and build all of our actual word logic via combinatorial parsers.
Scannerless Parsing
The single phase parsing process is known as Scannerless Parsing and there is already an excellent .Net implementation Sprache (The word is “Language” in German) which has been going for a good decade now.
Sprache
Sprache is a great library that has a full blown suite of combinatorial parsers and the ability to embed regex matches at any phase, consider some of the following we never even got near:
- DelimitedBy
- Repeat
- XOr
- Optional
- Once
- Not
There are a couple of other neat tricks they have, rather than returning a single object, it returns an array of 0 or 1 (and possibly in some scenarios more, I have not looked into concatenation), which means that it can be used directly with Linq and it can be written using the Linq Query syntax:
Parser<string> identifier =
from leading in Parse.WhiteSpace.Many()
from first in Parse.Letter.Once().Text()
from rest in Parse.LetterOrDigit.Many().Text()
from trailing in Parse.WhiteSpace.Many()
select first + rest;
I’ve done a third implementation of the original expression parser suite in Sprache, with the parsers split between the Token Parsers and Expression Parsers
We can look at the different ways to implement DayTime expression parser side by side:
// Linq Delegates Syntax
public static Parser<DayTime> DayTimeDelegate =
TokenParsers.DayOfWeek.Then(day =>
Parse.WhiteSpace.Then(_ =>
TokenParsers.LocalTime.Select(time =>
new DayTime(day, time))));
// Linq Query Syntax
public static Parser<DayTime> DayTimeLinqQuery =
from day in TokenParsers.DayOfWeek
from _ in Parse.WhiteSpace
from time in TokenParsers.LocalTime
select new DayTime(day, time);
Whitespace
It’s worth noting that we have to pay more attention to white space in the patterns. Scannerless parsing does not pre-process and package tokens, so they have to be sifted out of the whitespace / punctuation.
The tokeniser we have been using so far has been very basic and not taken into account white space or phrases that contain white space. A feature complete implementation would be able to shave regex matches off a string and move a cursor forward the length of the match.
Up Next
I’m going to do something completely different…
Credit
I’d like to credit Sprache for being a source of inspiration, and helping me bridge a couple of the concept gaps when trying to build both equivalent OO and Functional version of the same combinatorial parsers.
Header image by Gerd Altmann from Pixabay
