
This post was originally published on behalf of Checkout.com here.
Uptime
Here at Checkout.com, we process payments — and as the Wolf of Wall Street taught us, money never sleeps. It’s always flowing, 24 hours a day, 365.25 days a year.
As the engineering department for a company that processes payments, we cannot remain locked in stasis while the system runs. We have to be able to replace components and subsystems without interrupting the flow of traffic passing through the system.
Blue/Green deployments allow us to hot-swap systems already in use. Here, I cover the evolution of a simple server setup to a modern managed cluster and how Blue/Green deployments fit into the various systems configurations.
In the beginning
Let’s start with this basic setup. It’s a classic. The greybeards call it: Client/Server.
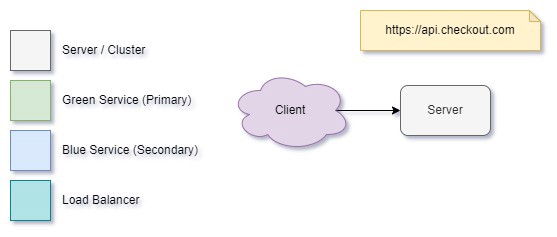
This… isn’t good enough to run a critical business. We can’t build a resilient, scalable system using this pattern. We’re limited to a single node that could fail, and a good rule of thumb is we should always run a minimum of two physical systems. With all the modern cloud systems we deploy to, it’s also pretty much impossible to avoid deploying to a cluster/load balancer setup anyway. Let’s represent that:
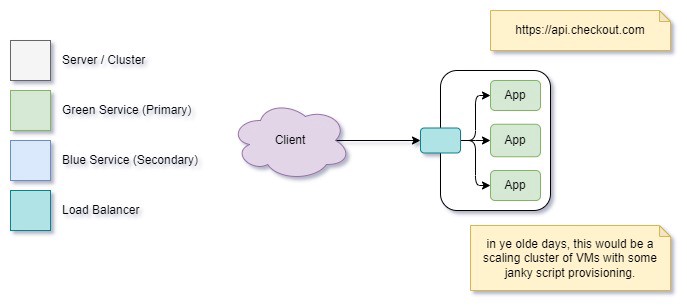
Great! Our app got deployed to a cluster, and now it’s being used. We’re running a successful business, money is rolling in, and everything is good. Now the business needs a new feature. We’ve developed it, tested it (it works on my machine!), and it’s all ready to go… let’s roll it out!
(I’ve used Octopus in our examples as it’s what we use; other deployment tools are available).
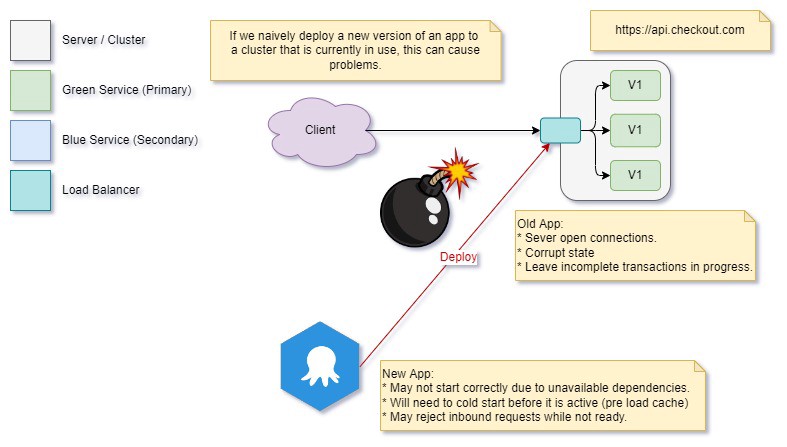
We’ve gone to our deployment system and pressed “deploy”. It’s pushed our package/container to the cluster, replacing our old app with new instances. And now we’ve got a couple of problems — at least in our completely contrived scenario:
- As we’re replacing our apps, some inbound connections will find the server they are trying to reach is in the process of an update, and we return some kind of failure, such as a 503 response.
- In the old app, some apps were not gracefully shut down. We have open transactions and locks on resources that were not released, so the new app may be locked out until these expire.
- In our new deployment, after we start it up, it doesn’t have the exchange rates (FX) in memory to process requests, and the API that provides them is not available. We can’t begin servicing requests.
- While we’re replacing the multiple app nodes, we also have no control or guarantee whether we are processing a given request with V1 or V2 of the system.
- At this point, our alerting system is screaming at us, and there’s nothing we can do about it. If we put the old system back, it will have the same problem with the FX API on start, so we’re still burning a hole in our service level agreement.
How do we avoid affecting our primary system while we deploy?
First, we need to have something to switch to — a secondary version of the app running in isolation. What does this system look like?
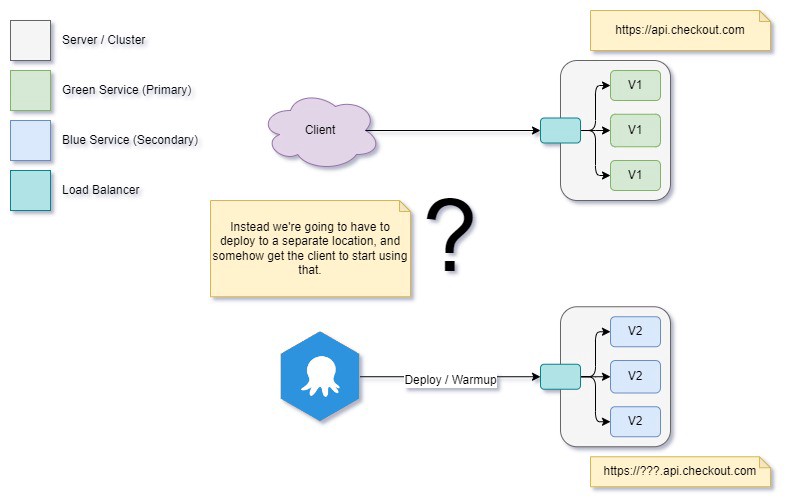
When we talk about Blue/Green deployment, we’re really talking about a pair of systems that can hand over to each other. How do we build a setup so we can handle hot-swapping our two systems? First, we need to bring both the original Green and the new Blue system under a single entry point, which will manage traffic between the two app clusters.
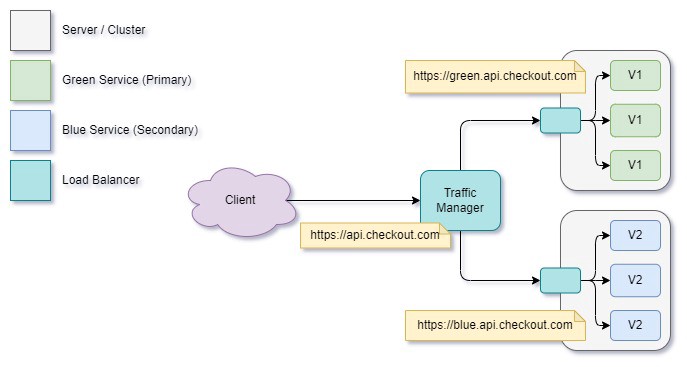
Now we have two separate systems behind a single entry point, which is invisible to the client. So how does our deployment system handle pushing to this new configuration, and how do we get our hot swap?
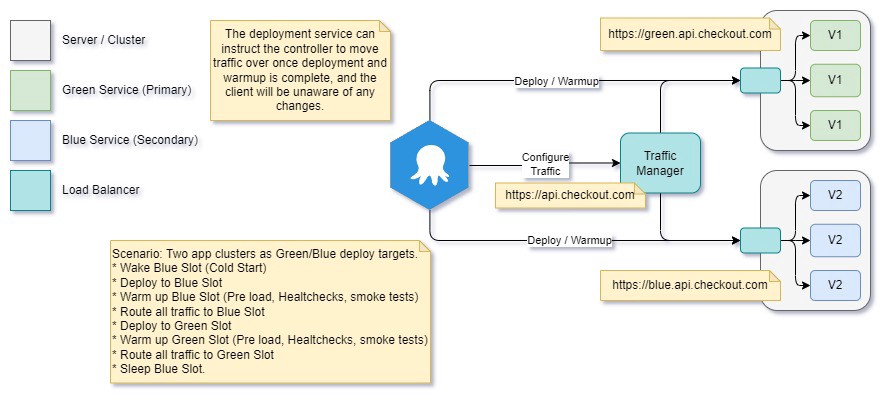
Magic!
Can we do anything to improve this? Currently, our swap is immediate, and we may still find a bug in our new app when we deploy to an environment and start running it at maximum load. Can we add any more confidence to our deployment?
Indeed we can. In the current setup, we instruct the traffic manager that acts as routing between our two systems to send all new connections to our secondary app at once — we can make this smoother.
To do so, we can gradually transfer traffic to the new service, keeping an eye on our logging system (such as DataDog) and confirming at each level of load that we’re not getting any errors until all traffic has been migrated.
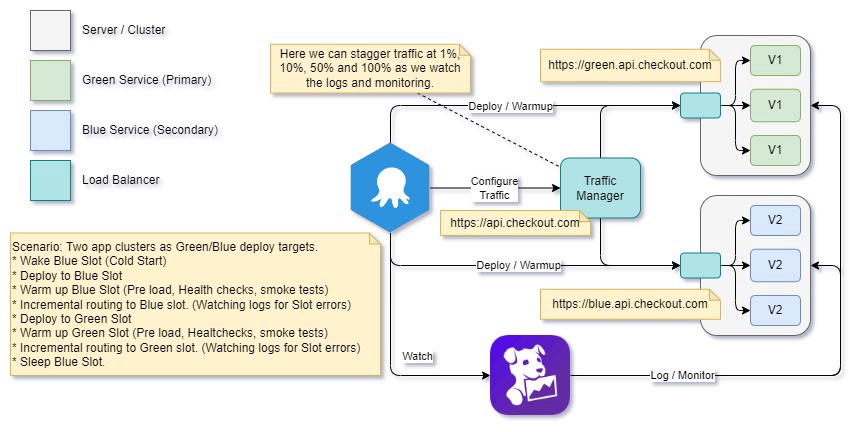
This process trades off deployment speed for a slower, more risk-averse approach. In critical areas of the business, this tradeoff makes sense as we can deploy the new version of our app with greater confidence.
Simplifying the System
As it stands, our system is composed of two clusters with their own load balancers, plus an additional traffic manager to handle routing between the two. Network hops are one of the more expensive considerations in a distributed system: how can we reduce these?
As all three components are responsible for handling network traffic, we could fold all the responsibilities for these together and make it run in a single hybrid cluster. If we do, we have a single controller for the cluster that handles both DNS routing and traffic management. If you’ve worked with Azure, the below setup used to support slot-based deployments will look familiar:
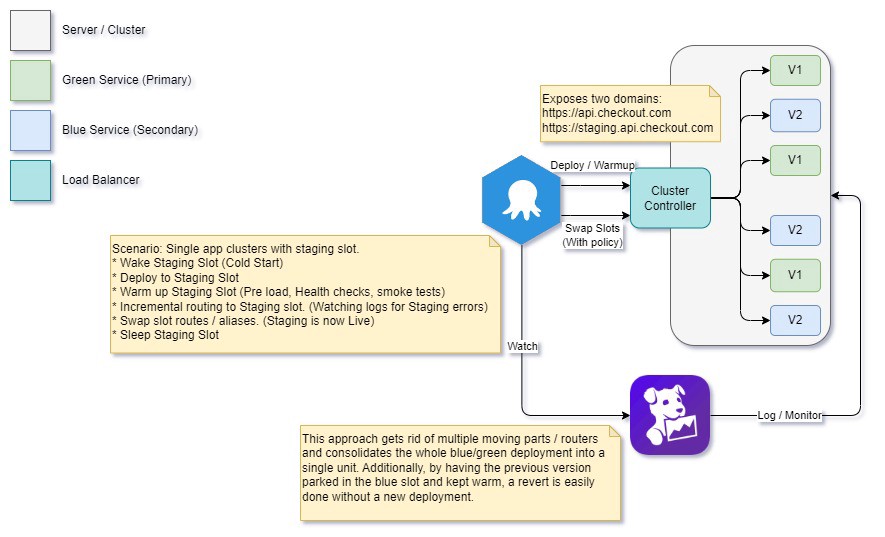
More magic!
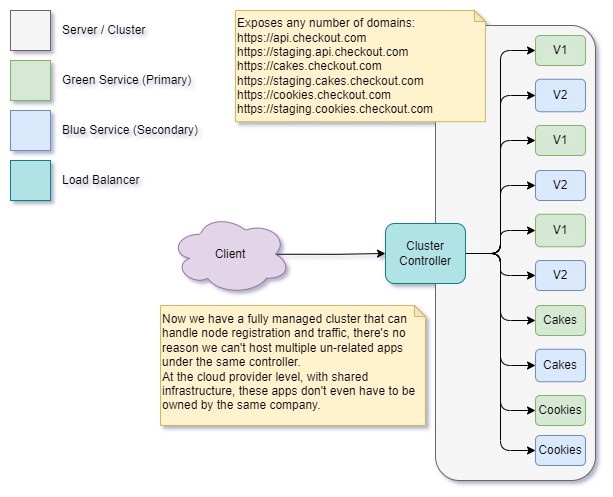
Modern Cluster
This brings us to where we are today with modern cluster management techniques used for ECS, function apps, lambdas, and automatic scale sets. They can support hybrid app hosting and slot-based deployments. Now, we live in a magical wonderland of containers and shared infrastructure that just scales up and down on-demand. We only pay for what we use a̶n̶d̶ ̶w̶e̶ ̶n̶e̶v̶e̶r̶ ̶h̶a̶v̶e̶ ̶t̶o̶ ̶w̶o̶r̶r̶y̶ ̶a̶b̶o̶u̶t̶ ̶c̶o̶-̶h̶o̶s̶t̶e̶d̶ ̶s̶e̶r̶v̶i̶c̶e̶s̶ ̶e̶a̶t̶i̶n̶g̶ ̶a̶l̶l̶ ̶o̶f̶ ̶o̶u̶r̶ ̶s̶h̶a̶r̶e̶d̶ ̶r̶e̶s̶o̶u̶r̶c̶e̶s̶ ̶a̶n̶d̶ ̶D̶O̶S̶i̶n̶g̶ ̶u̶s̶…
Alternative Implementations
We can take Blue/Green deployment principles and apply them in a couple of other ways.
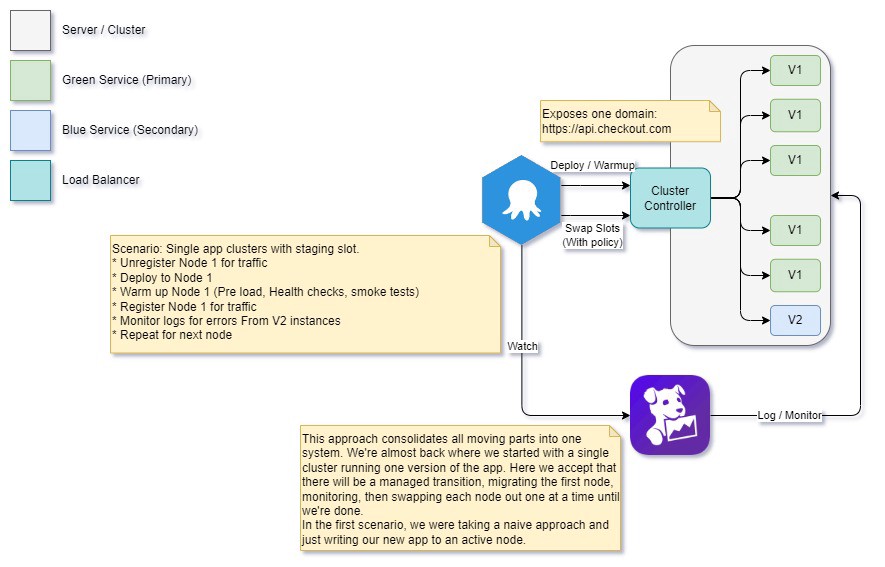
Canary deployment
Rather than deploying a complete cluster/node set and swapping, we can deploy to a single active node, observe how it runs under incremental load and replace the remaining nodes one at a time.
Canary Consumers
The same principle can be applied to queue consumers. A single throttled queue consumer (thread limits and delays) can be deployed and then monitored, with a policy in place to ramp up the consumer and then deploy the remainder.
Index/Database swaps
We can also use this approach to publish a new version of a data store/index. Create a new read-only database/index under an alias and change the default alias used by the read cluster — for example, changing the “main” database role to point to a new DB/Elasticsearch index.
The queries continue without interruption, but the new store is now returning results.
Limitations / Considerations
One of the key principles in this approach is backward compatibility. It is critical we do not deploy breaking changes to contracts or storage schemas/models, as this will cause errors when used by different versions. This is why when adding a new column or field, it’s important to ensure it is optional and, when removing one, to ensure that it’s not validated or a required field for serialization.
This is doubly important for data that has a temporal element and may live for a longer period of time outside a service — for example, scheduled messages — as it’s entirely possible we could have progressed multiple versions of an API or system ahead of where the message originated.
One strategy for managing this is to use versioned contracts and feature toggles where appropriate.
Wrap up
These techniques are part of the toolkit for building resilient systems and remain responsive through the development/deployment cycle. It’d be great to see more of these in production, particularly the local council waste collection site, which is usually down when I need to check the bin days…
Credits
Header photo by Tima Miroshnichenko from Pexels
